Introduction to ELT
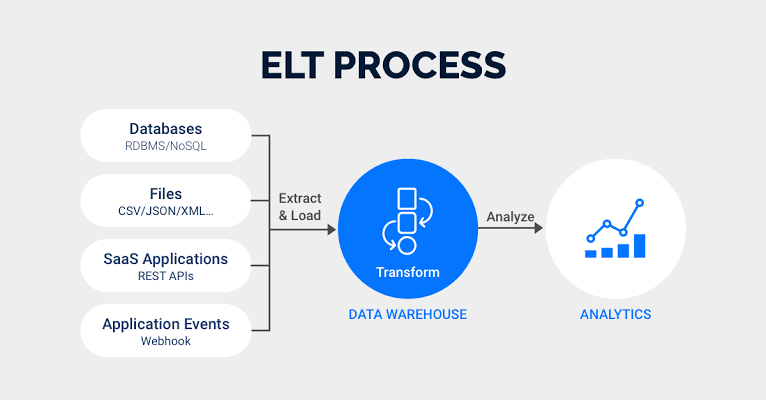
ELT (Extract, Load, Transform) helps streamline the tasks of managing Big Data and Modern Data Warehousing. This allows businesses to focus on mining their data for actionable insights. ELT leverages the target system to do the data transformation instead of transforming the data before it’s written. This approach needs fewer remote sources than other approaches since it needs only unprepared and raw data.
ETL vs ELT is an alternative to the traditional method of Data Migration, ETL. Its capability of pushing the transformation component of the process to the target database comes in handy when processing massive datasets. This can then be used for Big Data Analytics and Business Intelligence (BI). Since the ELT process leverages the processing capability of a data storage infrastructure, it effectively reduces the time spent by data in transit. It also significantly improves efficiency. ELT has become increasingly popular with the widespread use of Cloud-native Data Lakes and Hadoop.
Here is how the ELT process works:
- Extract: This step works similarly in both ELT and ETL Data Management approaches. Raw streams of data from software, applications and virtual infrastructure are either ingested completely or based on a specific set of predefined rules.
- Load: Instead of delivering raw data and loading it to an interim processing server for transformation, ELT can deliver it directly to the target storage location. This reduces the cycle length between Data Extraction and Data Delivery.
- Transform: The Data Warehouse or Database normalizes and sorts the data, keeping a part or all of it on hand and accessible for customized reporting. The data storage overhead is significantly higher, but it offers more opportunities to mine it for relevant Business Intelligence in near real-time.
Understanding the Benefits of ELT
You can use an ELT process to manage millions of records in the new data formats easily, as opposed to leveraging traditional Data Warehouses. Here are a few key benefits of leveraging ELT processes for your business use case:
- Lowering Costs: Similar to most Cloud-based services, Cloud-based ELT can lead to a lower total cost of ownership, since an upfront investment in hardware is often redundant.
- Flexibility: The ELT process is flexible and adaptable, therefore it’s suitable for a variety of applications, businesses and goals.
- Future-proofed Datasets: ELT implementation can be used directly for Data Warehousing systems. ELT can also be used in the Data Lake approach in which data is collected from a range of disparate sources. This helps simplify the process of making future changes to the Data Warehouse structure.
- Scalability: The scalability of a Cloud infrastructure and hosted services like Software-as-a-Service (SaaS) and integration-Platform-as-a-Service (iPaaS) provide organizations with the ability to expand resources on the go. They can add the storage space and compute time required for even massive Data Transformation tasks.
- Leveraging the Latest Technologies: ELT solutions can leverage the power of new technologies in order to push security, compliance, and improvements across the enterprise. ELT can also utilize the native capabilities of Big Data Processing frameworks and modern Cloud Data Warehouses.
- Simplifying Management: ELT can easily separate the transformation and loading tasks while streamlining project management, lowering risks, and minimizing the interdependencies between these processes.
When Should You Use ELT?
Since ETL transforms data prior to the loading stage, it is recommended when a destination requires a specific data format. This might include a situation when there’s a misalignment in supported data types between the destination and source, the limited availability to quickly scale processing in a destination, or security restrictions that make it impossible to store raw data in a destination.
ELT can be used when the destination is a Cloud-native Data Warehouse like Snowflake, Google BigQuery, Amazon Redshift, and Microsoft Azure SQL Data Warehouse. This is because organizations can transform their raw data at any time, when and as necessary for their use case, instead of a step in the Data Pipeline.
Conclusion
This blog gives a brief overview of a few key aspects of the ELT process. This includes a description of the working of this process, its benefits, and essential use cases.
A fully managed No-code Data Pipeline platform like Hevo Data with its minimal learning curve can be set up in just a few minutes allowing the users to load data without having to compromise performance. Its strong integration with umpteenth sources allows users to bring in data of different kinds in a smooth fashion without having to code a single line.